


碎碎念
配置完环境变量使用命令
source /bin/profile激活我才意识到原来一直使用的python环境激活source /venv/bin/activate中的这个activate居然也是一个文本文件,一直因为是一个看着还行文件webpack扒对应目标函数注入
1
2
3
4
5
6
7
8
9window.c = c;
window.res = "";
window.flag = false;
c = function(r){
if(flag){
window.res = window.res + `"${r.toString()}"` + ":" + (e[r] + "" ) + ",";
}
return window.c(r);
}python中的
map()map的作用是:把一个函数,应用到一堆数据的每一个元素上。1
2b=map(func,list) # 对list中的每一个函数都作用到 返回的是一个可迭代对象的地址
c=list(b) # list中每一个值都被func作用之后返回到的这个新的列表中python中的
zip()1
2
3
4
5aaa=[1,2,3,4,5,6]
bbb=[7,8,9,10,11,12]
ccc=[13,14,15,16,17,18]
ddd=zip(aaa,bbb,ccc) # 返回一个可迭代对象的地址
c=list(ddd) # 这样就可以拿来用了AI解释
zip是干嘛的?——“打包配对”想象一下你有三列队伍:
- 第一队(客户端基):
[+, x, +, ...] - 第二队(服务器基):
[x, x, +, ...] - 第三队(客户端极化):
[0, 1, 0, ...]
zip的作用就是让这三队人并排站好,一次各出一人,组成一个三人小组。- 第一队(客户端基):
计算机中用来加密解密运算的时候通常使用字节
计算机中的所有二进制数据确实都是以字节为基本单位存在和操作的**。比特更像是字节的”组成成分”,但计算机硬件层面直接处理的是字节。**也就是说在进行计算之前都得把值转换成byte然后才能进行运算
网络传输时,二进制数据通常编码为十六进制字符串(可读性好,避免特殊字符问题)
但异或运算需要在原始的字节层面进行,不能直接用字符串
格式 本质 主要用途 例子 比特 信息最小单位 位级操作、标志位、协议字段、按位运算 0b10110100字节 计算机基本单位 文件读写、网络通信、内存管理、加密解密、数据库储存 b'\xb4'十六进制 人类可读表示 调试显示、配置、数据交换 "b4"
软硬连接
基本理解
1
2
3ls -li file # 查看inode编号
ln file newfile # 创建一个硬链接 有一样的inode编号
ln -s file newfile # 创建一个软连接 inode编号不同主要区别
1
2
3
4
5
6
7对于硬链接:
hardlinkfile --> inode编号 --> 文件地址
sourcefile --> inode编号 --> 文件地址
对于软连接
sourcefile --> inode编号 --> 文件地址
softlinkfile --> sourcefile --> inode编号 --> 文件地址删除软连接源文件之后这个软连接就失效了,因为inode储存的是源文件地址
硬链接则不会失效
对于两种链接在无论哪边改动文件另一半的文件内容也会改变
windows的
\在github中无法解析成图片需要换成/1
find . -name "*.md" -exec sed -i 's/\(!\[[^]]*\]([^)]*\)\\/\1\//g' {} +
iptables设置端口禁用
一定要指定网卡 一定要指定协议 生效顺序是从上往下的 如果没有指定网卡 则本地(nginx)也接受不到
1
2iptables -A FORWARD -p tcp -i lo --dport 8000 -j ACCEPT
iptables -A FORWARD -p tcp -i eth3 --dport 8000 -j DROPpython中的with作用,主要是用来自动管理使用文件的资源管理
常规使用
1
2
3
4f = open("test.txt", "w")
f.write("Hello World")
# 如果这里中间的代码报错了,下面的 f.close() 永远不会执行
f.close()如果使用了with
1
2
3with open("test.txt", "w") as f:
f.write("Hello World")
# 代码执行完这一块,文件会自动关闭,即使中途报错了也会关掉with后面跟着的对象,必须是一个**“上下文管理器”**。它在底层逻辑上包含两个神奇的方法:__enter__:当你进入with语句块时,它先执行(比如:打开文件)。__exit__:当你离开with语句块时(无论是正常结束,还是因为代码报错崩溃了),它强制执行(比如:关闭文件、释放内存、断开数据库连接)。
也就是说相当于自动搞了个
try-finallywith解决的痛点
正如你之前提到的,操作系统有内存回收机制,但有些资源是操作系统没法帮你“乱猜”什么时候该回收的。比如:
- 文件占用:如果你在 Windows 下运行程序打开了一个文件没关,你可能无法在文件夹里删除这个文件,系统会提示“文件正在被另一个程序使用”。
- 网络/数据库连接:每个连接都占用服务器的槽位。如果不释放,服务器很快就会满员,拒绝新连接。
- 多线程锁 (Lock):在多线程编程中,如果不及时释放锁,整个程序就会死锁(卡死)。
linux如何查看占用某个端口的程序是什么
1
2ss -tanp | grep ':80'
ps -up 80
powershell小命令
密码的原来自己解压缩包的python应用想要使用
python -m http.server需要手动配置防火墙策略构造图片码的方法(/b是指使用二进制解析)
1
copy /b normal.jpg + shell.php malicious.jpg
powershell查询hash
1
Get-FileHash filepath
powershell检查数字签名 有效值
1
Get-AuthenticodeSignature Filepath
Windows系统日志自定义分类
使用Windows原生命令行
设置一个新的单独的windwos系统日志分类和新的日志源(全程添加的时候要使用管理员身份)
1
[System.Diagnostics.EventLog]::Exists("Testcategory") # 判断一个日志分类是否存在

1
New-EventLog -LogName "TestCategory" -Source "Test1" -ErrorAction Stop # 创建一个新的日志分类和日志源
需要注意的是: 事件源 (
Source) 的名称是全局唯一的。一旦你在注册表中注册了"Test1"这个事件源,系统会将其视为一个特定的程序或组件的唯一标识符。原有的日志情况
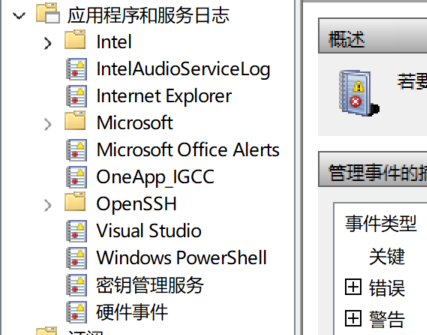
新的日志添加后的情况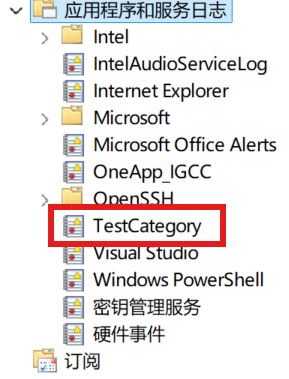
插入一个新的日志情况,需要注意的是,这个地方 必须是现有的日志源!
1
Write-EventLog -LogName "TestCategory" -Source "Test1" -EventId 1001 -EntryType Information -Message "测试事件:分类创建验证"
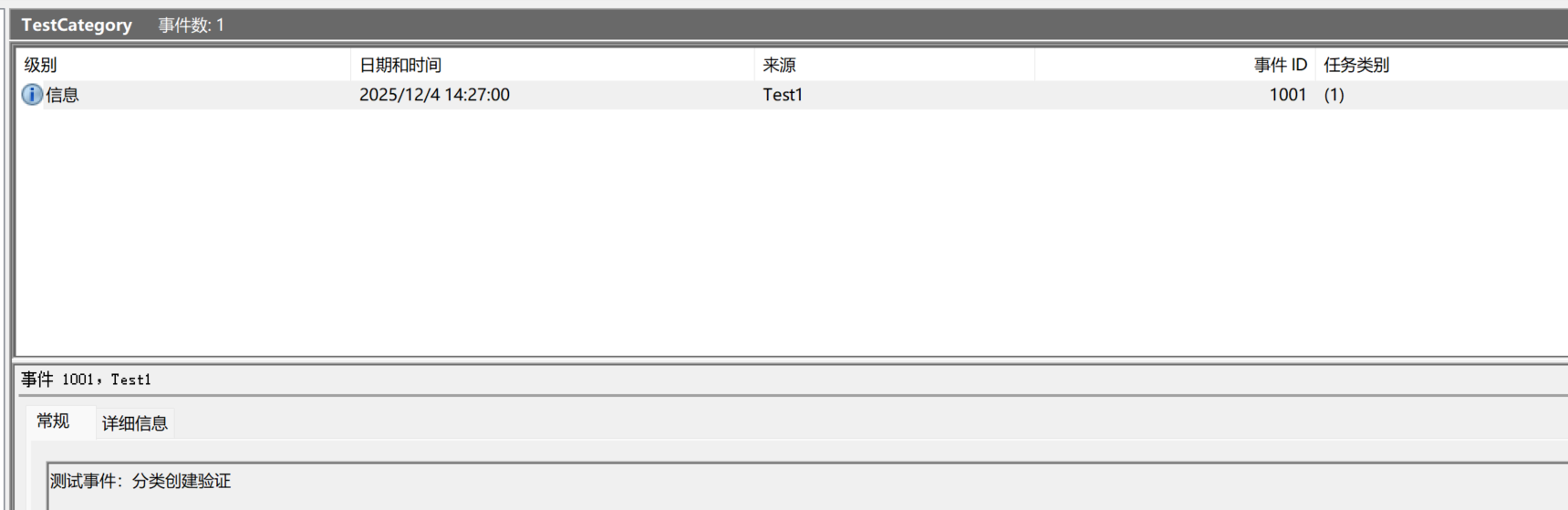
删除日志分类
1
Remove-EventLog -LogName TestCategory -ErrorAction SilentlyContinue
需要注意的是: 删除一个事件日志分类(LogName)时,与该分类相关联的所有事件源(Event Source)配置也会一并被删除。
python实现
需要注意的是python对于日志的操作全部是通过powershell实现的
使用python来实现自动新建事件源(需要管理员身份),自动插入日志(无需管理员身份),主要还是使用
subprocess来调用powershell查看系统日志分类存在情况
1
2
3
4
5
6
7
8
9
10
11
12# 方法1:使用简单的存在性检查
success, stdout, stderr = self._run_powershell_safe(
f'[System.Diagnostics.EventLog]::Exists("{self.category_name}")'
)
if success and "True" in stdout:
print(f"✅ 分类存在: {self.category_name}")
self._setup_complete = True
self._setup_event_source()
else:
print(f"❌ 分类不存在或检查失败: {self.category_name}")
self._setup_complete = False创建新的日志源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19success, stdout, stderr = self._run_powershell_safe(
f'[System.Diagnostics.EventLog]::SourceExists("{self.script_name}")'
)
if success and "True" in stdout:
print(f"✅ 事件源已存在: {self.script_name}")
return
else:
# 创建事件源
print(f"🔄 创建事件源: {self.script_name}")
success, stdout, stderr = self._run_powershell_safe(
f'New-EventLog -LogName "{self.category_name}" -Source "{self.script_name}"'
)
if success:
print(f"✅ 事件源创建成功")
else:
print(f"❌ 事件源创建失败")
print(stdout,stderr)
self._setup_complete = False写入日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16try:
# 写入事件日志
success, stdout, stderr = self._run_powershell_safe(
f'Write-EventLog -LogName "{self.category_name}" -Source "{self.script_name}" -EventId {event_id} -EntryType {level_map[level]} -Message "{message}"'
)
if success:
print("✅ 事件写入成功")
return True
else:
print(f"❌ 事件写入失败")
return False
except Exception as e:
print(f"❌ 写入异常: {e}")
return False完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
import subprocess
import sys
class FixedEncodingLogger:
"""修复编码问题的事件日志记录器"""
def __init__(self, category_name="AAAAHardwareProject", script_name="PriceMonitor"):
# 使用英文分类名称避免编码问题
self.category_name = category_name
self.script_name = script_name
self._setup_logging()
def _run_powershell_safe(self, command):
"""安全运行PowerShell命令,处理编码问题"""
try:
# 使用正确的编码和错误处理
result = subprocess.run(
["powershell", "-Command", command],
capture_output=True,
text=True,
encoding='gbk', # Windows系统默认编码
errors='ignore' # 忽略无法解码的字符
)
return result.returncode == 0, result.stdout, result.stderr
except Exception as e:
return False, "", str(e)
def _setup_logging(self):
"""设置日志系统"""
print(f"🔍 检查分类: {self.category_name}")
# 方法1:使用简单的存在性检查
success, stdout, stderr = self._run_powershell_safe(
f'[System.Diagnostics.EventLog]::Exists("{self.category_name}")'
)
if success and "True" in stdout:
print(f"✅ 分类存在: {self.category_name}")
self._setup_complete = True
self._setup_event_source()
else:
print(f"❌ 分类不存在或检查失败: {self.category_name}")
self._setup_complete = False
def _setup_event_source(self):
"""设置事件源"""
try:
# 检查事件源是否存在
success, stdout, stderr = self._run_powershell_safe(
f'[System.Diagnostics.EventLog]::SourceExists("{self.script_name}")'
)
if success and "True" in stdout:
print(f"✅ 事件源已存在: {self.script_name}")
return
else:
# 创建事件源
print(f"🔄 创建事件源: {self.script_name}")
success, stdout, stderr = self._run_powershell_safe(
f'New-EventLog -LogName "{self.category_name}" -Source "{self.script_name}"'
)
if success:
print(f"✅ 事件源创建成功")
else:
print(f"❌ 事件源创建失败")
print(stdout,stderr)
self._setup_complete = False
except Exception as e:
print(f"❌ 事件源设置失败: {e}")
self._setup_complete = False
def log(self, message, event_id=1000, level="info"):
"""记录日志"""
level_map = {"info": "Information", "warning": "Warning", "error": "Error"}
icons = {"info": "ℹ️", "warning": "⚠️", "error": "❌"}
print(f"{icons[level]} [{level.upper()}] {message}")
if not getattr(self, '_setup_complete', False):
return False
try:
# 写入事件日志
success, stdout, stderr = self._run_powershell_safe(
f'Write-EventLog -LogName "{self.category_name}" -Source "{self.script_name}" -EventId {event_id} -EntryType {level_map[level]} -Message "{message}"'
)
if success:
print("✅ 事件写入成功")
return True
else:
print(f"❌ 事件写入失败")
return False
except Exception as e:
print(f"❌ 写入异常: {e}")
return False
def info(self, message, event_id=1000):
return self.log(message, event_id, "info")
def warning(self, message, event_id=2000):
return self.log(message, event_id, "warning")
def error(self, message, event_id=3000):
return self.log(message, event_id, "error")
# 测试
if __name__ == "__main__":
logger = FixedEncodingLogger("AAAAHardwareProject", "Alert")
logger.info("🚀 测试修复编码问题")
logger.info("📊 这是一条测试消息")
git命令
git clone代理
1 | git -c http.proxy=socks5://127.0.0.1:20170 clone |
ssh key
生成密钥对
1 | ssh-keygen -t ed25519 -C "注释" |
然后判断要不要输入密码,直接回车就是无密码
需要注意的是这个命令生成的公私钥都是在本地的
上传公钥的命令
1 | ssh-copy-id -i ~/.ssh/123.pub root@ip |
或者直接传入公钥
1 | cat ./id_rsa.pub >> ~/.ssh/authorized_keys |
成功以后就能添加密钥
公钥登陆
1 | ssh -i ~/.ssh/123.pub root@ip |
或者使用config文件来配置快速登录,找到目录
1 | ~/.ssh/config |
添加
1 | Host |
awk速查
模式匹配
awk默认是条件+动作
;隔开语句1
2awk 'NR==2 || NR==11 {print $2}' # 只有一个语句
awk 'NR==2 ; NR==11 {print $2}' # 有两个语句, 没有动作默认print $0所以NR==2会整行打印-F参数的含义-F'[= ]'是awk的字段分隔符参数:**# 需要注意的是 awk默认使用空格来进行分割 **-F:指定字段分隔符(Field separator)'[= ]':这是一个正则表达式,表示按等号=或空格``进行分割
1
awk -F '[= ]' '{print $1}'
//使用正则表达式来进行定位 提到函数substr()1
ip a | awk '/^[0-9]+:/{ip=substr($2,1,length($2)-1);print ip}'
substr()命令解析substr(字符串, 开始位置, 长度)
-f读取awk命令文件-v定义变量传入1
awk -v ip='0.0.0.0' '{print ip}' file
awk都是按照file的按行读入,每一行都会执行一次
$n是分割开来的第几个,从1开始,$0就是表示第一行如果是本来就分割好的就能直接使用
$n1
df -h | awk '{print $1 $3}'
可以自己分割然后在使用
$n1
awk -F '[= ]' '{print $1}'
除了读取特定文件 awk还可以读取当前文件夹下的所有文件,但是必须是文件不能有文件夹 否则会报错
就是一个
*1
awk '/20202020/{print $0}' *
默认按照空格切分,例如以下例子。(需要注意的是awk关注单双引号闭合的情况,只会关注空格)
1
220.181.108.153 - - [20/Dec/2012:14:11:03 +0800] "GET /clim/climintro.jsp HTTP/1.1" 200 3270 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
$0是一整行,$1是第一个-,$8是200如果只在某个元素中进行匹配的方法
1
2awk '$7 ~ /\.jsp/{print $7}' *(当前目录下所有文件)/filename
awk 'match($7,/\.jsp/,a){print $7}' *if 的使用必须包裹在
{}但是可以不使用if就无需包裹1
2
3
4
5# 可以工作但不简洁
username_file=`awk '{if(NR==1) print $1}' user.txt`
# 更简洁的标准写法(推荐)
username_file=`awk 'NR==1{print $1}' user.txt`如果是使用正则匹配完希望打印匹配到的前后一定距离的东西(例如是在一个url中的最后一个文件,匹配后缀和前面的最后一个/) 使用函数
match()1
2
3
4
5awk 'match($7,/\/.*\.jsp/,a){print a[0]}' # 贪婪匹配 会匹配前面全部的/,不精确 -> /a/c/listClassification.jsp
awk 'match($7,/\/[^/]*\.jsp/,a){print(a[1])}}' #精确匹配 --> listClassification.jsp
awk '{n=split($7, a, "/"); if(a[n] ~ /\.jsp$/) print a[n]}' file #精确 --> listClassification.jsp命令解析
1
2
3
4
5awk '{
n=split($7, a, "/");
if(a[n] ~ /\.jsp$/)
print a[n]
}' file同10,这个地方可以不使用
if1
2
3
4awk '{
n = split($7,a,"/");
a[n] ~ /\.jsp$/ {print a[n]}
}' filen=split($7, a, "/");是对字符串$7进行按照/的分组,分完的组在a中,同时n是返回元素的个数if(a[n] ~ /\.jsp$/)和上面一样的逻辑,对某一个元素进行正则match()函数解析对于这样一个例子:
1
aaa/aaaa/vvv//sss/dsadw/vasdac/123.jsp?aaa=ssxx&xxx=asadw
如果仅仅想要匹配出
123.jsp但是不要其他内容,就要使用正则表达式1
match($7,/\/([^/]*\.jsp)/,a);print a[0]
正则表达式的解析:
/\/([^/*].jsp)/(1)
/.*/两侧的/使用来表示这个是一个正则表达式(2)
[^/]匹配不是/的内容,^是取反的意思(3) 也就是说这个匹配
/开始然后filename.jsp的内容(4) 这里面
a[0]是匹配到的所有东西/filename.jsp,a[1]是括号内的东西filename.jsp如果匹配多个(使用
|) 并且要删去某些匹配到脏东西的(多个条件用&&)1
2# 必须在linux环境下!或者是git bash
awk '/limit|/select|from|contract/{if($0 !~ /selectresult/ && $0 ~ /\.jsp/)}' *按照某个值进行排序然后输出(提到函数)
1
2
3
4
5
6
7
8awk '/select|limit|from|concat/ && !/selectResult/ {
count[$1]++
}
END {
for(ip in count) {
print count[ip], ip
}
}' ex180223.log | sort -nr命令解析:
sort-n按照数字排序-r降序排序-u去重-k指定排序字段如何按照时间进行排序?
1
2
3
4
5
6# 如果实在同一天可以直接把时间转化为一个肉眼可见的数字
awk '/banner_home.jpg/
{n=split($4,time1,":");
time2=time1[n]+time1[n-1]*100+time1[n-2]*10000;
print(time2,$0)}
' ex180223.log | sort -n | head
手动解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22awk '/banner_home.jpg/{
# 时间格式: 23/Feb/2018:09:04:58
split($4, datetime, "[/:]");
day = datetime[1];
month = datetime[2];
year = datetime[3];
hour = datetime[4];
minute = datetime[5];
second = datetime[6];
# 月份名称转数字
month_num = (month=="Jan") ? 1 : (month=="Feb") ? 2 :
(month=="Mar") ? 3 : (month=="Apr") ? 4 :
(month=="May") ? 5 : (month=="Jun") ? 6 :
(month=="Jul") ? 7 : (month=="Aug") ? 8 :
(month=="Sep") ? 9 : (month=="Oct") ? 10 :
(month=="Nov") ? 11 : 12;
# 创建可排序的时间戳
timestamp = sprintf("%04d%02d%02d%02d%02d%02d", year, month_num, day, hour, minute, second);
print timestamp, $0;
}' ex180223.log | head其实还有新的办法使用函数 使用函数
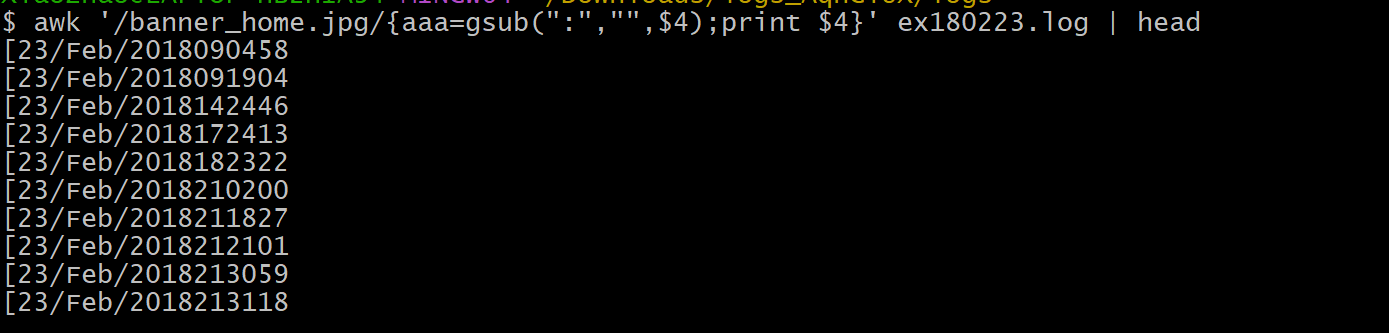
gsub()这是一个全局替换函数,可以吧匹配处理啊的东西全部替换,和 **
sub()**的区别就是sub()只匹配第一个1
aaa = gsub(正则表达式,需要替换后的内容,需要替换的部分) # 会在原来的数据上直接修改,aaa是记录替换多少个值
1
awk '/banner_home.jpg/{aa=gsub(":","",$4);print $4}' filename | head
BEGIN模块
这个模块只在开始的时候执行一次,可用性十分广泛,在处理任何输入数据之前执行一次性设置或初始化操作。
各种使用参数
变量 作用 示例 FS设置输入字段分隔符。 BEGIN{FS=","}:告诉awk以逗号分隔输入行。OFS设置输出字段分隔符。 BEGIN{OFS="\t"}:设置输出字段之间使用制表符(Tab)。RS设置输入记录分隔符。 BEGIN{RS="."}:如您第二个例子所示,设置以点号分隔记录。ORS设置输出记录分隔符。 BEGIN{ORS="---"}:设置每行输出结束后追加---而不是默认的换行符。对上述表格的解析: 字段是每一行的每一列, 记录默认是按照’\n’来进行分割,感官上就是一行一个记录
1
awk 'BEGIN{RS="."};{print $0}' ifconfig12.txt
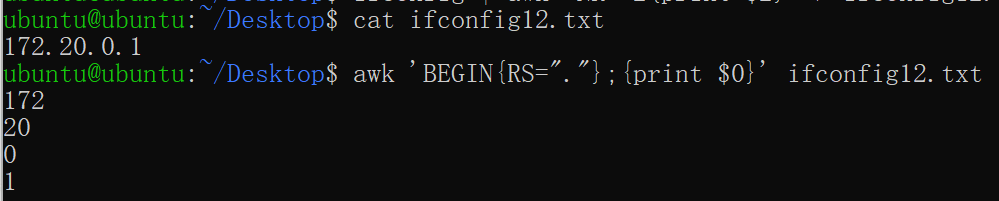
也可以按照模块来表达格式
1
2
3
4awk '
BEGIN{RS='.';}
{print $0;}
' ifconfig12.txt初始化变量
初始化自定义变量,用于在后续的数据处理块中进行计数、累加或状态跟踪。
- 示例:
BEGIN{count=0; sum=0}- 在开始处理文件之前,将
count和sum初始化为 0。
- 在开始处理文件之前,将
- 示例:
打印头部或报告标题
在处理数据之前,打印报告的标题或列头。
- 示例:
BEGIN{print "--- 报告标题 ---"; print "编号\t姓名\t分数"}- 在读取文件数据前,先输出一个清晰的标题和列名。
- 示例:
格式化打印
print1
awk '{print "ip:"$2, "netmask:"$4, "broadcoast:"$6}' ifconfig13.txt

printf1
2awk '{printf "%-6s%-20s%-10s%-20s%-10s%-20s\n",$1,$2,$3,$4,$5,$6}' ifconfig13
.txt格式说明符 含义 字段应用 %-5s左对齐 ( -),占用 5 个字符的宽度 (5),以字符串 (s) 形式打印。打印 $1(例如:inet或ether)%-20s左对齐,占用 20 个字符的宽度。 打印 $2(例如:172.20.0.1或02:42:d5:6d:8c:31)%-10s左对齐,占用 10 个字符的宽度。 打印 $3(例如:netmask或txqueuelen)%-20s左对齐,占用 20 个字符的宽度。 打印 $4(例如:255.255.0.0或0)\n换行符,在格式化输出后另起一行。 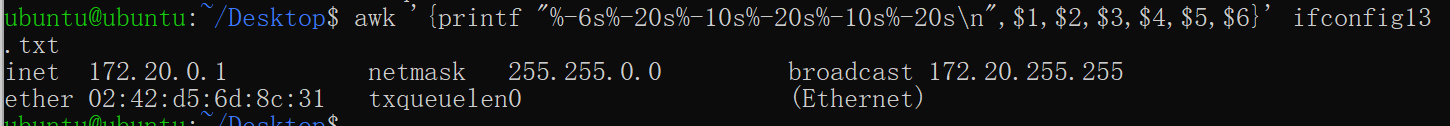
grep速查
在都是文本文件的文件夹中查找
'aaa'1
grep -r 'aaa' fold
1
2
3
4fold
| - - 1.txt
| - - 2.txt
| - - 3.txt如果希望加上正则表达式可以使用
-E,如果要搜索文件夹使用-r
如果实在文件夹中使用正则表达式使用-rE
CTF观察
string居然可以查pcap
1
string 1.pcap | grep flag
GPG公钥过期解决方法
类似报错
1
2
3
4
5
6
7
8
9
10
11Err:9 https://apt.v2raya.org v2raya InRelease
The following signatures were invalid: EXPKEYSIG 354E516D494EF95F mzz2017 (apt) <mzz@tuta.io>
Fetched 11.1 MB in 3s (4,158 kB/s)
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
280 packages can be upgraded. Run 'apt list --upgradable' to see them.
W: https://download.docker.com/linux/ubuntu/dists/jammy/InRelease: Key is stored in legacy trusted.gpg keyring (/etc/apt/trusted.gpg), see the DEPRECATION section in apt-key(8) for details.
W: An error occurred during the signature verification. The repository is not updated and the previous index files will be used. GPG error: https://apt.v2raya.org v2raya InRelease: The following signatures were invalid: EXPKEYSIG 354E516D494EF95F mzz2017 (apt) <mzz@tuta.io>
W: Failed to fetch https://apt.v2raya.org/dists/v2raya/InRelease The following signatures were invalid: EXPKEYSIG 354E516D494EF95F mzz2017 (apt) <mzz@tuta.io>
W: Some index files failed to download. They have been ignored, or old ones used instead.区分是否是小众软件,如果是的话(像这个v2raya,就可以直接去官网上寻找公钥地址)
1
2rm /etc/apt/keyrings/v2raya.asc
wget -qO - https://apt.v2raya.org/key/public-key.asc | sudo tee /etc/apt/keyrings/v2raya.asc禁用更新该原件源
1
2# 删除 /etc/apt/sources.list.d 中的文件
sudo rm -f /etc/apt/sources.list.d/v2raya.list
python处理网络数据包
使用
scapy库进行处理from scapy.all import * packets = rdpcap('./bb84_attack.pcapng') packets[0] # 第一个数据包 packets[1] # 第二个数据包 每个数据包中层级 packets[0][TCP] packets[0][Raw] # 获取Raw层对象 packets[0][Raw].load # 获取原始字节数据:b'seed:123456789'1
2
3
4
5
6
7
8
9
3. 提取数据
```python
# 步骤1:提取种子
raw_bytes = packets[0][Raw].load # b'seed:123456789'
decoded_text = raw_bytes.decode() # 'seed:123456789'
seed_text = decoded_text.split(":")[1] # '123456789'
seed = int(seed_text) # 123456789判断层级 需要注意的是这样只能获取原始载荷 无法获取多个数据包组成的数据流(例如http)
1
2
3if i.haslayer(TCP): # 判断是否有TCP层
if i.haslayer(Raw): # 判断是否有Raw层
print(i.getlayer(Raw).load) #其实这个和print(i[Raw].load)是一个效果追踪流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15sessions = packets.sessions()
for session, session_packets in sessions.items():
print(f"\n会话: {session}")
for pkt in session_packets:
if pkt.haslayer(TCP) and pkt.haslayer(Raw):
raw_data = pkt[Raw].load
# 判断是否为HTTP数据
if b'HTTP' in raw_data:
print(f"HTTP响应: {raw_data[:200]}...")
elif b'GET' in raw_data or b'POST' in raw_data:
print(f"HTTP请求: {raw_data[:200]}...")
else:
print(f"TCP数据: {raw_data[:100]}...")
字符集规则
ANSI是Ascii的扩充码
ascii使用的是一个字节的低7位,本来是考虑最高一位用来拓展,但是不够,衍生出了ANSI,总共有65536个
2^16每个国家按照这个ANSI标准来创造自己的编码规则例如
gbk---但是还是发现这个ANSI不好用,每个国家都有自己的编码,于是出现了全球统一编码
unicode,使用2^32但是发现他很浪费unicode在网络传输中很难用,非常的浪费,很多是空值,而且还很容易和其他的二进制流(图片视频)来出现混淆但是在内存层面使用
unicode是合适的,因为长度固定,容易寻址,并且操作系统具有内存回收操作(满了自动删或者重启全都删)不怕浪费可变长度的
unicode就是utf,存在多个版本utf-8,utf-16…..utf-8最小长度的字符是8bit-1Byte,utf-16最小长度的字符是16bit/2B所有文字的传输和存储都必须使用
utf-8/gbk转换成字节1
2aaa = "我爱你"
aaa.encode(编码集)
utf-8的编码逻辑
字符长度可变,最短就是8bit/1B
ascii中的就使用1B欧洲那些就是2B
中文(
gbk)3B天坑
1
2
3
4
5## 天坑
print(b"c" == b"\x63") ==> True # 这就是因为11.1.1中直接显示的就是ascii
bbb = b"\xaa\xca\xaa" # 正常情况下,\x后面跟着两个十六进制表示一个B 这里面的字节分别是\xaa \xca \xaa这3个
ccc = b"\xaac\xcc\xbbb" #在这种情况下就是utf和ascii混用的情况,字节分别是\xaa c \xcc \xbb b求二进制串长度
1
print(ccc.__len__())
控制字符区别LF和CRLF
属于是不同阵营(linux/windows)的控制字符(如何进行换行表示?)
windwos认为换行必须先把光标放到最前面, linux认为直接换行就好了
什么是 LF 和 CRLF?
这两个词起源于老式电传打字机时代,代表了两个不同的机械动作:
术语 全称 转义符 动作含义 LF Line Feed \n换行:纸张向上卷一行,但打字头还在原来的水平位置。 CR Carriage Return \r回车:打字头迅速回到当前行的起始(最左边)位置。 CRLF CR + LF \r\n回车换行:打字头回最左边,且纸张向上卷一行。 主要区别是占用空间不一样, LF一个B,CRLF2个B
git提交的时候统一使用LF,会自动转换
高级语言读入内存时统一认为是
\n
nginx 配置
颁发双向tls证书
1
2
3
4
5
6
7
8
9openssl req -x509 -newkey rsa:4096 -nodes -keyout ./ca.key -out ./ca.crt -subj "/CN=domainname" -days 3650
openssl req -newkey rsa:2048 -nodes -keyout ./server.key -out ./server.csr -subj "/CN=domainname"
openssl x509 -req -in server.csr -out ./server.crt -CA ./ca.crt -CAkey ./ca.key -CAcreateserial -days 3650
openssl req -newkey rsa:2048 -nodes -keyout ./client.key -out ./client.csr -subj "/CN=domainname"
openssl x509 -req -in client.csr -out ./client.crt -CA ./ca.crt -CAkey ./ca.key -CAcreateserial -days 3650但是python中需要使用的是pem
1
cat client.crt client.key > client_bundle.pem
1
2
3
4
5client = requests.Session()
client.verify = './ssl/ca.crt' # CA证书
client.cert = './ssl/client_bundle.pem' # 客户端证书
response = client.post()nginx配置双向tls认证
实际上这个双向认证的证书和tls验证的证书是分开的,也就是说可以使用一个脚本去每90天更新一次免费的
https_tls证书,但是一直使用同一份双向tls认证证书1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45....
http{
....
##
# SSL Settings
##
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3; # Dropping SSLv3, ref: POODLE
ssl_prefer_server_ciphers on;
server {
listen 443 ssl;
server_name _;
# Nginx 服务器自身的证书和私钥
ssl_certificate /etc/nginx/ssl/certs/server.crt;
ssl_certificate_key /etc/nginx/ssl/private/server.key;
# 客户端证书颁发机构 (CA) 的根证书
ssl_client_certificate /etc/nginx/ssl/certs/ca.crt;
# mTLS 核心配置
ssl_verify_client on;
ssl_verify_depth 1;
# 修改location块以正确处理请求
location /api/abc {
# 使用proxy_pass直接转发,避免rewrite带来的问题
proxy_pass http://127.0.0.1:8000/;
# 保留所有HTTP方法和头部信息
proxy_method $request_method;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket支持
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
}
其他文章

从理论到实践:NFC/ID 卡复制与攻防技术详解
- 26/03/08
- 14:32
- 技术