http请求走私
高质量文章
学好此文,国家赠送金手铐和职业套装,数年管吃管住-HTTP请求夹带(HTTP request smuggling)_请求夹带是什么-CSDN博客
http版本区别
http 1.1
http 1.1支持pipline就是支持在一个http包中放入两个请求,比如上面一个POST下面一个GET, 比如说上面是合法包,下面是payload. 前端只检测了合法包就通过了这个http请求包就会让payload在后端加载.keepalive当出现这个就是告诉服务器http请求没有请求完,就会把刚才没法完的内容接上去
http 2
使用
Transfer-Encoding,当出现0\r\n\r\n,也就是0和两个回车(如代码块)就结束了1
20
http头格式区别
1
2
3
4:method GET
:path /anything
:authority vulnerable-website.com
:scheme https://evil-user.net/poison?
出现原因
现代大型网络多采用前后端分离技术(
front-endback-end),就是设置了类似负载均衡(负载均衡、反向代理、网关等)和后面的服务端分离的架构,这些服务在链路上起到了一个转发请求给后端服务器的作用,因为位置位于后端服务器的前面,所以本文把他们称为前端服务器。实际上主要
Connect的设置主要是延长服务器中缓存的停留时间, 如果keep-alive不同的中间件或者网关会设置不同的通信时间, 如果设置时间内一直没有收到新的消息, 则也会主动关闭. 但是缓存中对于上一个包的消息中的干扰消息(对于完整的HTTP报文已经读取,还留下没有被认为完全传输的,但实际上适用于干扰的信息)不会立刻删除, 而是按照指定时间删除, 而且一般在上一个包中模棱两可的东西也会干扰服务器对这个连接的关闭判断从而延长关闭. 当服务器缓存中有这个东西, 而有发送了一个新的包的时候就可以继续运行了. 所以和Keep-Alive与Closed没有本质关系而是与是否缓存被删除有关系.- 同时对于
HTTP 1.1来说,默认使用的就是Keep-Alive,如果不经过特殊设置得到的就是这个. - 所以说对于
Connect的设置并不是必要的
- 同时对于
对数据包的结束的判断标准
使用
Content-Length进行判断,header中标记Content-Length有多长,就按照这个来截取数据包(使用burp repeater可以自动计算长度,但是在实际开始应用的时候关闭这个功能burp -> send旁边 -> Update Connect Length)使用
Transfer-Encoding进行判断,当包中最后一个是0时认为数据包结束,Transfer-Encoding头则可以声明消息体使用了chunked编码,就是消息体被拆分成了一个或多个分块传输,每个分块的开头是当前分块大小(以十六进制表示),后面紧跟着\r\n,然后是分块内容,后面也是\r\n。消息的终止分块也是同样的格式,只是其长度为零。例如:1
2
3
4
5
6
7
8POST /search HTTP/1.1
Host: normal-website.com
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
b
q=smuggling
0
当前后端对包的结束点确认方法不同的时候出现http请求走私漏洞(
http requests smuglling)HTTP 规范为了避免这种歧义,其声明如果
Content-Length和Transfer-Encoding同时存在,则Content-Length应该被忽略。某些服务器不支持请求中的
Transfer-Encoding头。某些服务器虽然支持
Transfer-Encoding头,但是可以通过某种方式进行混淆,以诱导不处理此标头。如果前端服务器(转发服务)和后端服务器处理
Transfer-Encoding的行为不同,则它们可能在连续请求之间的边界上存在分歧,从而导致请求走私漏洞。就是构造一个GPOST包,就是一个包包含GET请求有包含POST请求
元宝解释从tcp链路层角度的漏洞出现原因
在通过TCP传输HTTP报文时,设备(如代理服务器、负载均衡器或目标服务器)解析HTTP报文的方式取决于TCP的流式传输特性以及HTTP协议本身的设计。以下是详细的解答:
TCP的流式传输特性
TCP是一个面向流的协议,它将应用层的数据视为一个连续的字节流(byte stream),而不关心数据的具体边界。TCP会将应用层的数据分段(segmentation)传输,并在接收端重新组装这些段(reassembly)。因此,TCP本身并不保留应用层数据的边界信息。
- 发送端:TCP将HTTP报文分成多个TCP段(segments),每个段的大小受限于最大报文段长度(MSS)和网络路径的MTU(最大传输单元)。
- 接收端:接收方会根据TCP的序列号将这些段重新组装成一个完整的字节流。
HTTP协议的解析方式
HTTP协议是基于文本的协议,它依赖于请求行、请求头和请求体的特定格式来解析报文。HTTP协议的解析是在应用层完成的,而不是在TCP层。
- HTTP/1.1:HTTP/1.1是基于文本的协议,请求报文和响应报文由明确的边界(如换行符
\r\n)分隔。接收方需要从TCP的字节流中解析出完整的HTTP报文。 - HTTP/2:HTTP/2是二进制协议,报文被分割成帧(frames),每帧都有明确的类型和长度。接收方需要按照HTTP/2的帧结构解析报文。
- 事实上从这里就可以看出不同版本对于边间分隔的区别, 这也是漏洞成因
设备如何解析HTTP报文?
设备在解析HTTP报文时,通常是从TCP的字节流中逐步读取数据,并根据HTTP协议的规则解析出完整的报文。具体过程如下:
(1)逐段读取TCP数据
- TCP层会将接收到的TCP段交给应用层(如HTTP协议栈)。
- 应用层会从TCP的字节流中逐步读取数据,直到解析出一个完整的HTTP请求或响应。
(2)根据HTTP协议规则解析
- HTTP/1.1:应用层会查找
\r\n\r\n(请求头和请求体之间的分隔符)或\r\n(请求行和请求头之间的分隔符),以确定请求的边界。 - HTTP/2:应用层会根据帧的类型和长度字段解析出完整的帧,并将这些帧重新组装成HTTP报文。
(3)处理不完整的报文
- 如果接收到的TCP段不足以组成一个完整的HTTP报文,设备会等待更多的TCP段到达,直到解析出完整的报文为止。
- 这种等待可能会导致延迟,尤其是在网络条件较差或攻击者故意发送不完整请求的情况下。
是否需要等待整个HTTP包的TCP碎片?
答案是:不需要等待整个HTTP包的所有TCP碎片到达,但需要等待一个完整的HTTP报文被解析出来。
- TCP层的特性:TCP会将所有属于同一个连接的段按顺序交付给应用层,因此应用层可以逐步读取数据并解析。
- HTTP层的特性:HTTP协议的解析依赖于报文的完整性(如请求行、请求头和请求体的分隔符),因此应用层必须等待足够的数据到达,才能解析出一个完整的HTTP报文。
HTTP请求走私与解析方式的关系
HTTP请求走私攻击利用了TCP的流式传输特性和HTTP协议的解析方式之间的不一致性。具体来说:
- 代理服务器和目标服务器的解析差异:代理服务器和目标服务器可能对同一个TCP字节流有不同的解析结果。例如,代理服务器可能认为一个请求已经完整,而目标服务器认为该请求尚未结束。
- 不完整的HTTP报文:攻击者可以故意发送不完整的HTTP报文,利用TCP的分段传输特性,使得代理服务器和目标服务器对请求的解析结果不同。
- 总结
- TCP层:TCP将HTTP报文分段传输,并在接收端重新组装成一个字节流。设备不需要等待所有TCP段到达,但需要等待一个完整的HTTP报文被解析出来。
- HTTP层:HTTP协议的解析依赖于报文的完整性,因此设备需要从TCP的字节流中逐步读取数据,直到解析出一个完整的HTTP报文。
- HTTP请求走私:攻击者利用TCP的分段传输特性和HTTP协议的解析方式之间的不一致性,构造出模棱两可的请求,导致代理服务器和目标服务器对请求的解析结果不同。
这种解析方式的差异是HTTP请求走私攻击的核心原因之一。元宝解释从tcp链路层角度的漏洞出现原因
在通过TCP传输HTTP报文时,设备(如代理服务器、负载均衡器或目标服务器)解析HTTP报文的方式取决于TCP的流式传输特性以及HTTP协议本身的设计。以下是详细的解答:
TCP的流式传输特性
TCP是一个面向流的协议,它将应用层的数据视为一个连续的字节流(byte stream),而不关心数据的具体边界。TCP会将应用层的数据分段(segmentation)传输,并在接收端重新组装这些段(reassembly)。因此,TCP本身并不保留应用层数据的边界信息。
- 发送端:TCP将HTTP报文分成多个TCP段(segments),每个段的大小受限于最大报文段长度(MSS)和网络路径的MTU(最大传输单元)。
- 接收端:接收方会根据TCP的序列号将这些段重新组装成一个完整的字节流。
HTTP协议的解析方式
HTTP协议是基于文本的协议,它依赖于请求行、请求头和请求体的特定格式来解析报文。HTTP协议的解析是在应用层完成的,而不是在TCP层。
- HTTP/1.1:HTTP/1.1是基于文本的协议,请求报文和响应报文由明确的边界(如换行符
\r\n)分隔。接收方需要从TCP的字节流中解析出完整的HTTP报文。 - HTTP/2:HTTP/2是二进制协议,报文被分割成帧(frames),每帧都有明确的类型和长度。接收方需要按照HTTP/2的帧结构解析报文。
- 事实上从这里就可以看出不同版本对于边间分隔的区别, 这也是漏洞成因
设备如何解析HTTP报文?
设备在解析HTTP报文时,通常是从TCP的字节流中逐步读取数据,并根据HTTP协议的规则解析出完整的报文。具体过程如下:
(1)逐段读取TCP数据
- TCP层会将接收到的TCP段交给应用层(如HTTP协议栈)。
- 应用层会从TCP的字节流中逐步读取数据,直到解析出一个完整的HTTP请求或响应。
(2)根据HTTP协议规则解析
- HTTP/1.1:应用层会查找
\r\n\r\n(请求头和请求体之间的分隔符)或\r\n(请求行和请求头之间的分隔符),以确定请求的边界。 - HTTP/2:应用层会根据帧的类型和长度字段解析出完整的帧,并将这些帧重新组装成HTTP报文。
(3)处理不完整的报文
- 如果接收到的TCP段不足以组成一个完整的HTTP报文,设备会等待更多的TCP段到达,直到解析出完整的报文为止。
- 这种等待可能会导致延迟,尤其是在网络条件较差或攻击者故意发送不完整请求的情况下。
是否需要等待整个HTTP包的TCP碎片?
答案是:不需要等待整个HTTP包的所有TCP碎片到达,但需要等待一个完整的HTTP报文被解析出来。
- TCP层的特性:TCP会将所有属于同一个连接的段按顺序交付给应用层,因此应用层可以逐步读取数据并解析。
- HTTP层的特性:HTTP协议的解析依赖于报文的完整性(如请求行、请求头和请求体的分隔符),因此应用层必须等待足够的数据到达,才能解析出一个完整的HTTP报文。
HTTP请求走私与解析方式的关系
HTTP请求走私攻击利用了TCP的流式传输特性和HTTP协议的解析方式之间的不一致性。具体来说:
- 代理服务器和目标服务器的解析差异:代理服务器和目标服务器可能对同一个TCP字节流有不同的解析结果。例如,代理服务器可能认为一个请求已经完整,而目标服务器认为该请求尚未结束。
- 不完整的HTTP报文:攻击者可以故意发送不完整的HTTP报文,利用TCP的分段传输特性,使得代理服务器和目标服务器对请求的解析结果不同。
- 总结
- TCP层:TCP将HTTP报文分段传输,并在接收端重新组装成一个字节流。设备不需要等待所有TCP段到达,但需要等待一个完整的HTTP报文被解析出来。
- HTTP层:HTTP协议的解析依赖于报文的完整性,因此设备需要从TCP的字节流中逐步读取数据,直到解析出一个完整的HTTP报文。
- HTTP请求走私:攻击者利用TCP的分段传输特性和HTTP协议的解析方式之间的不一致性,构造出模棱两可的请求,导致代理服务器和目标服务器对请求的解析结果不同。
这种解析方式的差异是HTTP请求走私攻击的核心原因之一。
攻击类型分类
CL.TE类型
构造在同一个包
构建payload如下,注意需要将repeater -> inspector -> request attributes中设置成HTTP 1.1
1 | POST / HTTP/1.1 |
对于前端服务器来说就是完整的35个长度的包放过去了(Content-Length)
但是对于后端服务器来说,到0就结束了 后面的会被存留在服务器中, 有下一个请求过来就会以为是这个GET的请求,将会被直接返回
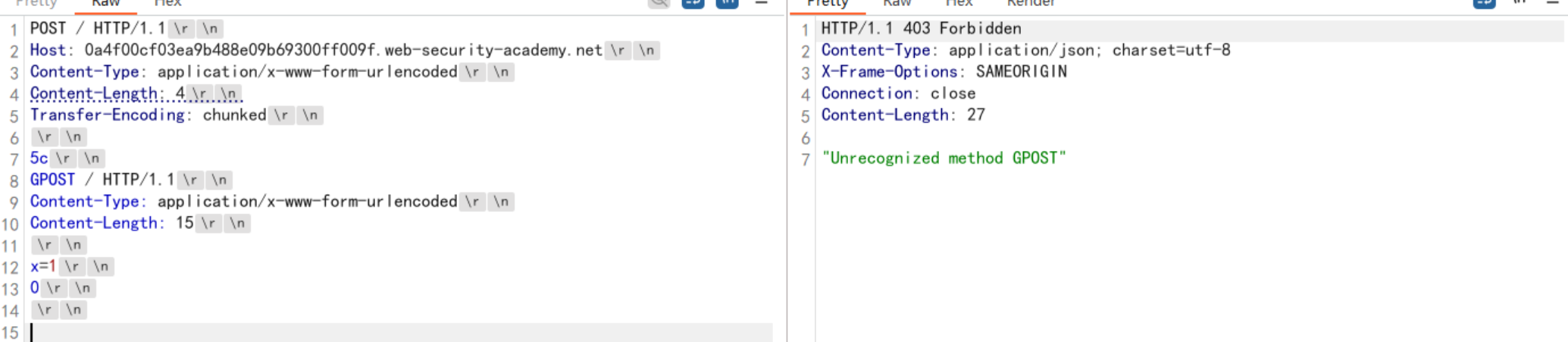
bp官方思路
1 | Content-Type: application/x-www-form-urlencoded |
构造GPOST 前端服务器使用TE,到0就截止了,不会吧G传给后端服务器,而是在那里等着tcp的下一步连接.
下次上传的POST就会和这个G结合变成GPOST,因为不和规范而报错
CSDN思路
1 | POST / HTTP/1.1 |
此种情况下,前端服务器支持Transfer-Encoding标头,会将消息体视为分块编码方式,它处理第一个长度为8字节的数据块,内容是SMUGGLED,之后解析处理第二个块,它是0长度,因此解析终止。该请求转发到后端服务器后,由于后端服务器采用Content-Length标头,按照其中请求主体长度的3个字节,解析会执行到8之后的行开头,所以SMUGGLED及以下的内容就不会被处理,后端服务器会将余下内容视为请求序列中下一个请求的起始。
插件http requests smuglling
1 | GET / HTTP/2 |
HTTP 2伪头部特殊性在 HTTP/2 协议中,伪头部(如
:method、:path、:authority)是强制且唯一的,用于定义请求的核心元数据。若请求中重复出现伪头部(例如你的请求中有两个:path),理论上应被拒绝。但在实际场景中,部分服务器(尤其是降级为 HTTP/1.x 的代理)可能未严格校验,导致以下问题:
前端与后端解析不一致:前端代理可能仅处理第一个
:path,而后端服务器可能取最后一个或拼接两者,导致路径歧义。降级时的意外行为:HTTP/2 伪头部在降级为 HTTP/1.x 时需转换为请求行和 Host 头。若存在重复伪头部,降级逻辑可能生成异常的 HTTP/1.x 请求行(如
),触发后端路由错误.
TE.CL类型
1 | POST / HTTP/1.1\r\n |